Introduction to Data, Database, Database System, DBMS:
Data:
Data refers to a collection of facts, statistics, or information that is represented in a structured or unstructured format. It can be in the form of numbers, text, images, audio, video, or any other form of representation. Data can be processed, analyzed, and interpreted to extract meaningful insights and support decision-making.
Database:
A database is an organized collection of data that is stored and managed in a structured manner. It provides a way to store, retrieve, update, and manage large amounts of data efficiently. Databases are designed to ensure data integrity, security, and consistency. They are used in various applications and industries to store and manage structured information.
Database System:
A database system refers to the combination of a database and the software used to manage and access that database. It includes the database management system and other supporting components. A database system provides an interface for users and applications to interact with the database, perform operations such as querying and updating data, and ensure data integrity and security.
DBMS (Database Management System):
A database management system (DBMS) is a software application that enables users to define, create, manipulate, and manage databases. It provides an interface for users to interact with the database, perform operations such as querying and modifying data, and ensure the integrity and security of the data. DBMSs handle tasks such as data storage, retrieval, concurrency control, transaction management, and data backup and recovery.
In summary, data is the collection of facts or information, a database is an organized collection of data, a database system is the combination of a database and its management software, and a DBMS is the software application used to manage and access the database.
Advantages of Using DBMS:
Database Management Systems (DBMS) offer several advantages in managing and organizing data effectively. Here are some key advantages of using DBMS:
1. Data Integration and Centralization:
DBMS allows for the centralization of data, where multiple users and applications can access and manage data from a single source. This eliminates data redundancy and inconsistency, ensuring that all users work with consistent and up-to-date information.
2. Data Security and Access Control:
DBMS provides robust security mechanisms to protect data from unauthorized access, ensuring data confidentiality, integrity, and availability. Access controls can be implemented to restrict user access to specific data or functionalities based on user roles and privileges.
3. Data Consistency and Integrity:
DBMS enforces data integrity constraints, such as uniqueness, referential integrity, and domain constraints, to maintain data consistency and accuracy. It prevents the entry of invalid or inconsistent data, ensuring the reliability of the stored information.
4. Data Backup and Recovery:
DBMS offers built-in mechanisms for data backup and recovery, allowing for the creation of data backups and the ability to restore data in case of system failures, errors, or data corruption. This helps to protect valuable data and minimize the risk of data loss.
5. Data Sharing and Collaboration:
DBMS enables data sharing and collaboration among multiple users and applications. It provides concurrent access to data, allowing multiple users to access and modify the data simultaneously, ensuring data consistency and coordination.
6. Data Scalability and Performance:
DBMS is designed to handle large volumes of data efficiently. It provides optimization techniques, indexing, and caching mechanisms to improve data retrieval and query performance, ensuring scalability as data grows.
7. Data Independence:
DBMS offers data independence, allowing changes to the database structure (schema) without affecting the applications using the database. This provides flexibility in adapting to evolving business requirements and simplifies database maintenance.
In summary, DBMS provides advantages such as data integration, security, consistency, backup and recovery, sharing and collaboration, scalability, performance, and data independence, making it a valuable tool for managing and organizing data effectively.
Field, Record, Objects, Primary Key, Alternate Key, Candidate Key:
Field:
A field refers to a single piece of data within a database or a record. It represents a specific attribute or characteristic of an entity. For example, in a database of employees, fields could include employee ID, name, date of birth, and salary. Each field has a specific data type and represents a specific piece of information.
Record:
A record, also known as a row or tuple, is a collection of related fields that represents a complete set of information about an entity or an object. In a database, a record represents a single instance or occurrence of an entity. For example, in a database of students, each record would contain fields such as student ID, name, address, and contact information for a specific student.
Objects:
In the context of databases, objects typically refer to complex data structures or entities that can be stored and manipulated within the database. Objects can encapsulate data and associated behaviors or methods. Object-oriented databases (OODBs) are specifically designed to work with objects, allowing for more advanced data modeling and manipulation capabilities compared to traditional relational databases.
Primary Key:
A primary key is a unique identifier for a record in a database table. It ensures that each record can be uniquely identified and serves as a reference point for linking and retrieving data from related tables. A primary key must have a unique value for each record and cannot contain null values. It provides a way to enforce data integrity and establish relationships between tables in a relational database.
Alternate Key:
An alternate key, also known as a secondary key, is a candidate key that is not chosen as the primary key. In a database table, there can be multiple alternate keys that can uniquely identify a record. While they are not used as the primary means of identifying records, alternate keys can still be used to ensure data uniqueness and serve as additional indexing or searching criteria.
Candidate Key:
A candidate key is a field or a combination of fields in a database table that can uniquely identify each record. It is a potential candidate for being selected as the primary key. A candidate key must satisfy the uniqueness and minimality criteria, meaning that it must have a unique value for each record, and no subset of its fields can also uniquely identify records. Multiple candidate keys may exist in a table, and one of them is chosen as the primary key.
In summary, a field represents a single piece of data, a record is a collection of related fields, objects are complex data structures, a primary key uniquely identifies a record, an alternate key is a secondary unique identifier, and a candidate key is a potential primary key choice.
DDL (Data Definition Language) and DML (Data Manipulation Language):
DDL (Data Definition Language):
Data Definition Language (DDL) is a set of SQL (Structured Query Language) statements used to define and manage the structure or schema of a database. DDL focuses on defining and modifying database objects such as tables, views, indexes, and constraints. Some commonly used DDL statements include:
CREATE:
The 'CREATE' statement is used to create new database objects such as tables, views, indexes, or schemas. The syntax for creating a table is as follows:
CREATE TABLE table_name (column1 datatype, column2 datatype, ...);
ALTER:
The 'ALTER' statement is used to modify the structure of existing database objects. It allows you to add, modify, or delete columns, constraints, or indexes in a table, for example. The syntax for adding a column to a table is as follows:
ALTER TABLE table_name ADD column_name datatype;
DROP:
The 'DROP' statement is used to delete or remove existing database objects such as tables, views, indexes, or schemas. The syntax for dropping a table is as follows:
DROP TABLE table_name;
TRUNCATE:
The 'TRUNCATE' statement is used to remove all data from a table while keeping its structure intact. The syntax for truncating a table is as follows:
TRUNCATE TABLE table_name;
DML (Data Manipulation Language):
Data Manipulation Language (DML) is a set of SQL statements used to manipulate or interact with the data within a database. DML statements focus on retrieving, inserting, updating, and deleting data in database tables. Some commonly used DML statements include:
SELECT:
The 'SELECT' statement is used to retrieve data from one or more database tables based on specified conditions. It is used for querying and retrieving data from the database. The syntax for selecting data from a table is as follows:
SELECT column1, column2, ... FROM table_name WHERE condition;
INSERT:
The 'INSERT' statement is used to insert new rows or records into a database table, providing the values for the columns of the table. The syntax for inserting data into a table is as follows:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
UPDATE:
The 'UPDATE' statement is used to modify or update existing data in a database table. It allows you to change the values of specific columns based on specified conditions. The syntax for updating data in a table is as follows:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
DELETE:
The 'DELETE' statement is used to delete specific rows or records from a database table based on specified conditions. The syntax for deleting data from a table is as follows:
DELETE FROM table_name WHERE condition;
In summary, DDL (Data Definition Language) is used to define and manage the structure or schema of a database, including creating, modifying, or deleting database objects. On the other hand, DML (Data Manipulation Language) is used to manipulate or interact with the data within the database, including retrieving, inserting, updating, and deleting data.
Database Models: Network Model, Hierarchical Model, Relational Database Model
Network Model:
The Network Model is a database model that represents data in a network-like structure. It is based on the concept of records and sets of relationships between them. In this model, data is organized as a collection of records connected through pointers or links. Each record can have multiple parent and child records, allowing for complex relationships. The Network Model was popular in the 1960s and 1970s and was used to model hierarchical data structures.
Hierarchical Model:
The Hierarchical Model is a database model that represents data in a tree-like structure with a strict one-to-many relationship between records. In this model, data is organized in a hierarchical manner, where each record has a single parent record and zero or more child records. The hierarchical structure is suitable for representing parent-child relationships and is commonly used in file systems and organizational structures. The Hierarchical Model was widely used in the early days of database management systems.
Relational Database Model:
The Relational Database Model is a database model based on the concept of tables, rows, and columns. It represents data as a collection of related tables, where each table consists of rows (records) and columns (attributes). The relationships between tables are established through keys, such as primary keys and foreign keys. The Relational Database Model provides a flexible and powerful way to organize and query data, allowing for efficient storage, retrieval, and manipulation of structured information. It is the most widely used database model in modern database management systems.
In summary, the Network Model organizes data in a network-like structure with multiple relationships, the Hierarchical Model represents data in a tree-like structure with strict parent-child relationships, and the Relational Database Model organizes data in tables with relationships established through keys.
Concept of Normalization: 1NF, 2NF, 3NF
1NF (First Normal Form):
First Normal Form (1NF) is the basic level of normalization that ensures the elimination of duplicate data and the organization of data into atomic values. In 1NF, each column of a table should contain only atomic (indivisible) values, and there should be a unique identifier for each row. Here's an example of a table that violates 1NF:
| Student ID | Student Name | Course |
|---|---|---|
| 1 | Santosh | Math, Physics |
| 2 | Hari | Chemistry |
To convert this table into 1NF, we need to remove the multiple values in the 'Course' column and create a separate row for each course taken by a student:
| Student ID | Student Name | Course |
|---|---|---|
| 1 | Santosh | Math |
| 1 | Santosh | Physics |
| 2 | Hari | Chemistry |
2NF (Second Normal Form):
Second Normal Form (2NF) builds upon 1NF and addresses the issue of partial dependencies in a table. A table is in 2NF if it is in 1NF and all non-key attributes depend fully on the entire primary key. Here's an example of a table that violates 2NF:
| Order ID | Product Name | Product Category |
|---|---|---|
| 1 | iPhone X | Mobile Phones |
| 1 | MacBook Pro | Laptops |
In this example, the 'Product Category' attribute depends on the 'Product Name' attribute, which is a partial dependency. To convert this table into 2NF, we need to separate the dependent attributes into a separate table:
| Order ID | Product Name |
|---|---|
| 1 | iPhone X |
| 1 | MacBook Pro |
| Product Name | Product Category |
|---|---|
| iPhone X | Mobile Phones |
| MacBook Pro | Laptops |
3NF (Third Normal Form):
Third Normal Form (3NF) builds upon 2NF and addresses the issue of transitive dependencies in a table. A table is in 3NF if it is in 2NF and all non-key attributes depend only on the primary key and not on other non-key attributes. Here's an example of a table that violates 3NF:
| Employee ID | Employee Name | Department | Department Location |
|---|---|---|---|
| 1 | Ram | Accounting | New York |
| 2 | Shyam | Marketing | Los Angeles |
In this example, the 'Department Location' attribute depends on the 'Department' attribute, which is a transitive dependency. To convert this table into 3NF, we need to separate the dependent attributes into a separate table:
| Employee ID | Employee Name | Department |
|---|---|---|
| 1 | Ram | Accounting |
| 2 | Shyam | Marketing |
| Department | Department Location |
|---|---|
| Accounting | New York |
| Marketing | Los Angeles |
In summary, normalization (1NF, 2NF, 3NF) is a process of organizing data in a database to eliminate data redundancy and improve data integrity. Each level of normalization has specific rules and criteria to ensure data is properly structured and dependencies are appropriately handled.
Centralized vs Distributed Database
A centralized database and a distributed database are two different approaches to storing and managing data. Here's a comparison of the key characteristics of each:
| Centralized Database | Distributed Database |
|---|---|
|
|
In a centralized database, all data is stored in a single location, and there is a central authority responsible for managing and controlling the database. Users access the data from this central location, and the database provides a unified view of the data. This approach is easier to maintain and manage since there is a single point of control.
In contrast, a distributed database consists of multiple database systems that are spread across different locations. Each database system is controlled and maintained by its own authority. Users can access data from multiple locations, and the database provides a fragmented view of the data. Managing a distributed database is more complex as it requires coordination between multiple authorities and handling data synchronization and consistency.
Both centralized and distributed databases have their advantages and considerations. The choice between them depends on factors such as data availability, scalability, data security, and the specific requirements of the application or organization.
Database Security
Database security is a critical aspect of maintaining the confidentiality, integrity, and availability of data stored in a database. It involves implementing various security measures to protect the database from unauthorized access, data breaches, and other security threats. Here are some important considerations and measures for ensuring database security:
Access Control:
Access control mechanisms are used to restrict and manage user access to the database. This includes implementing authentication and authorization mechanisms to ensure that only authorized users can access the database and perform specific actions. User roles and privileges should be defined and enforced to control access at various levels.
Data Encryption:
Data encryption is the process of converting sensitive data into an unreadable form to protect it from unauthorized access. Encryption techniques, such as symmetric and asymmetric encryption, can be used to encrypt data at rest and in transit. This helps in safeguarding the confidentiality of sensitive information stored in the database.
Auditing and Logging:
Auditing and logging mechanisms should be implemented to track and monitor activities within the database. This involves recording user actions, database modifications, and system events. Audit logs can be used for forensic analysis, identifying security breaches, and detecting suspicious activities.
Backup and Recovery:
Regular database backups should be performed to ensure data availability and facilitate recovery in the event of data loss or system failures. Backups should be securely stored and tested for restoration. Additionally, disaster recovery plans and procedures should be in place to minimize downtime and ensure business continuity.
Vulnerability Management:
Regular vulnerability assessments and patch management are essential to identify and address potential security vulnerabilities in the database system. This includes keeping the database software up to date with the latest security patches and fixes, as well as regularly scanning for vulnerabilities and applying necessary security measures.
Data Masking and Anonymization:
Data masking and anonymization techniques can be employed to protect sensitive data by substituting or masking personally identifiable information (PII) with fictional or generalized values. This helps in minimizing the risk of data exposure and maintaining privacy.
Physical Security:
Physical security measures, such as securing server rooms, restricting physical access to database servers, and implementing surveillance systems, are important for protecting the physical infrastructure that houses the database servers.
Implementing a comprehensive database security strategy involves a combination of technical controls, policies, procedures, and user awareness. It requires regular monitoring, updating security measures, and staying vigilant against evolving security threats.
Basic Elements of a Communication System
A communication system is a framework that allows the transmission and reception of information between two or more parties. It involves various components that work together to ensure effective communication. Here are the basic elements of a communication system:
1. Transmitter:
The transmitter is the device or system that converts the information or message into a suitable form for transmission. It encodes the message into a signal that can be transmitted through a communication channel. Examples of transmitters include microphones, cameras, and modulators.
2. Communication Channel:
The communication channel is the medium through which the encoded signal is transmitted from the transmitter to the receiver. It can be wired or wireless and may include physical mediums such as cables, fiber optics, or wireless mediums such as radio waves or satellite links.
3. Receiver:
The receiver is the device or system that captures the transmitted signal from the communication channel. It decodes the received signal back into the original message or information. Examples of receivers include speakers, displays, and demodulators.
4. Noise:
Noise refers to any unwanted disturbances or interference that affects the quality of the transmitted signal. It can arise from various sources such as electromagnetic interference, background noise, or signal distortions. Noise can degrade the signal and impact the accuracy of the communication.
5. Encoder and Decoder:
Encoders and decoders are components that perform the encoding and decoding processes, respectively. Encoders convert the message into a suitable signal format for transmission, while decoders reverse the process and extract the original message from the received signal.
6. Modulation:
Modulation is the process of modifying the characteristics of a carrier signal to carry the information being transmitted. It involves changing the amplitude, frequency, or phase of the carrier signal based on the input message. Modulation techniques include amplitude modulation (AM), frequency modulation (FM), and phase modulation (PM).
7. Demodulation:
Demodulation is the process of extracting the original message from the modulated carrier signal at the receiver end. It involves reversing the modulation process and recovering the original signal by detecting and interpreting the variations in the carrier signal.
8. Feedback:
Feedback is a mechanism that allows the receiver to provide information or acknowledgement back to the transmitter. It helps in ensuring the reliability and accuracy of the communication by enabling error detection and correction.
These basic elements form the foundation of a communication system and are essential for the successful transmission and reception of information between the sender and the receiver.
Communication Modes: Simplex, Half Duplex, and Full Duplex
In the field of telecommunications and computer networking, different communication modes are used to define the direction and flow of data transmission between communicating devices. The three main communication modes are simplex, half duplex, and full duplex. Let's explore each mode:
| Communication Mode | Description | Example |
|---|---|---|
| Simplex | In simplex mode, communication is unidirectional, meaning data can only flow in one direction. One device acts as the transmitter, and the other device acts as the receiver. The receiver can only receive data and cannot send a response back. | Television broadcasting, where the viewers can only receive the broadcasted content and cannot send any feedback or responses. |
| Half Duplex | In half duplex mode, communication is bidirectional but not simultaneous. Devices can both transmit and receive data, but not at the same time. Each device takes turns to transmit and receive data. | Two-way radios, where users must press a button to switch between transmitting and receiving modes. |
| Full Duplex | In full duplex mode, communication is bidirectional and simultaneous. Devices can transmit and receive data at the same time, allowing for real-time, two-way communication. | Telephone conversations, where both parties can speak and listen simultaneously. |
It's important to choose the appropriate communication mode based on the requirements of the specific application. Simplex mode is suitable for scenarios where data needs to be transmitted in one direction only. Half duplex mode is useful when two-way communication is required but not simultaneously. Full duplex mode enables real-time, simultaneous communication between devices.
Concept of LAN and WAN
LAN and WAN are two common types of computer networks that serve different purposes and cover different geographical areas. Let's understand the concepts of LAN (Local Area Network) and WAN (Wide Area Network):
Local Area Network (LAN):
A LAN is a computer network that covers a small geographical area, typically within a single building or a group of nearby buildings. It connects computers and devices in close proximity, allowing them to share resources, such as files, printers, and internet access. LANs are commonly used in homes, offices, schools, and other small-scale environments.
Key characteristics of a LAN include:
LANs are typically established and managed by individuals or organizations to facilitate efficient local communication and resource sharing among connected devices.
Wide Area Network (WAN):
A WAN is a computer network that covers a large geographical area, spanning multiple cities, countries, or even continents. It connects multiple LANs or other networks together, allowing for long-distance communication and data exchange. WANs are often established by service providers or telecommunications companies.
Key characteristics of a WAN include:
WANs enable organizations to connect their remote locations, branch offices, and data centers, providing access to centralized resources, such as databases, servers, and cloud services. They are designed to facilitate communication over longer distances and across different networks.
In summary, LANs are local networks that cover a small area and are used for local communication and resource sharing, while WANs are wide networks that span large areas, connecting multiple LANs and facilitating long-distance communication.
Transmission Medium: Guided and Unguided
In telecommunications and computer networks, the transmission medium refers to the physical pathway or channel through which data is transmitted from one device to another. There are two main types of transmission media: guided and unguided. Let's explore each type:
Guided Transmission Medium:
Guided transmission media, also known as bounded or wired media, are physical mediums that provide a direct and controlled path for data transmission. These media use cables or wires to transmit signals between devices. Here are some examples of guided transmission media:
| Medium | Description |
|---|---|
| Twisted Pair Cable | A type of cable that consists of pairs of insulated copper wires twisted together. It is commonly used for Ethernet networking. |
| Coaxial Cable | A cable that consists of a central conductor surrounded by an insulating layer, a metal shield, and an outer insulating layer. It is used for cable TV and broadband internet connections. |
| Fiber Optic Cable | A cable that transmits data as pulses of light through optical fibers made of glass or plastic. It offers high bandwidth and is used for long-distance communication. |
Guided transmission media provide a secure and controlled environment for data transmission, as the signals are confined within the physical boundaries of the cables or wires.
Unguided Transmission Medium:
Unguided transmission media, also known as unbounded or wireless media, do not rely on physical cables or wires to transmit signals. Instead, they use wireless communication technologies to transmit data through the air or space. Here are some examples of unguided transmission media:
| Medium | Description |
|---|---|
| Radio Waves | Electromagnetic waves that are used for various wireless communication applications, such as radio broadcasting and Wi-Fi. |
| Microwaves | High-frequency electromagnetic waves that are used for point-to-point communication, such as microwave links for long-distance transmission. |
| Infrared | Electromagnetic waves with shorter wavelengths than radio waves. Infrared is used for short-range communication, such as remote controls and infrared data transfer. |
Unguided transmission media allow for wireless communication, enabling devices to transmit and receive signals without the need for physical connections. They offer mobility and flexibility but may be susceptible to interference and signal degradation due to environmental factors.
In summary, guided transmission media use physical cables or wires to transmit data, providing a controlled pathway for communication. On the other hand, unguided transmission media employ wireless technologies to transmit signals through the air or space, enabling wireless communication between devices.
Transmission Impairments Terminology
Transmission impairments refer to the degradation or disturbances that can occur during the transmission of data over a communication system. Understanding these impairments is crucial for maintaining the quality and reliability of data transmission. Let's explore some common terminologies related to transmission impairments:
| Term | Description |
|---|---|
| Jitter | Variances in the timing of received signals, causing small but rapid fluctuations in the signal's arrival time. Jitter can result in data errors and affect the quality of real-time applications. |
| Singing | Undesirable oscillations or ringing in the transmitted signal, typically caused by improper impedance matching or reflections in the transmission line. Singing can distort the signal and lead to data errors. |
| Echo | The reflection of a portion of the transmitted signal back to the sender, resulting in a delayed and attenuated version of the original signal. Echoes can cause communication issues and interfere with the clarity of voice and audio signals. |
| Crosstalk | Undesired coupling or interference between adjacent communication channels or transmission lines. Crosstalk can cause signal distortion and data corruption, especially in scenarios where multiple signals are transmitted simultaneously. |
| Distortion | Alteration or deformation of the original signal waveform during transmission. Distortion can result from various factors, such as noise, interference, attenuation, or non-linearities in the transmission medium. It can affect the accuracy and integrity of the received data. |
| Noise | Unwanted or random electrical signals that interfere with the desired signal during transmission. Noise can arise from various sources, such as electrical interference, thermal noise, or electromagnetic radiation. It can degrade the signal quality and introduce errors. |
| Bandwidth | The range of frequencies or the capacity of a communication channel to carry data. Bandwidth determines the maximum data rate that can be transmitted. Insufficient bandwidth can lead to data loss or reduced transmission quality. |
| Number of Receivers | The count of devices or receivers connected to a transmission medium. The number of receivers can impact the signal strength, as well as introduce signal attenuation or degradation, particularly in scenarios where multiple receivers share the same medium. |
Understanding these terminologies helps in diagnosing and addressing transmission issues, implementing appropriate mitigation strategies, and ensuring reliable data transmission across communication systems.
Basic Concepts of Network Architecture: Client-Server and Peer-to-Peer
Network architecture refers to the structure and organization of a computer network, defining how devices and resources are interconnected and how information is exchanged. Two fundamental concepts of network architecture are the client-server model and the peer-to-peer model.
1. Client-Server Architecture:
In a client-server architecture, the network consists of two types of entities: clients and servers. The clients are end-user devices such as desktop computers, laptops, smartphones, or tablets. The servers are powerful computers or dedicated network devices that provide services, resources, or data to clients upon request.
The key characteristics of the client-server architecture are:
2. Peer-to-Peer Architecture:
In a peer-to-peer architecture, all devices or nodes in the network can act as both clients and servers. Each device has its own resources and can directly communicate and share files or services with other devices without relying on a centralized server.
The key characteristics of the peer-to-peer architecture are:
Both client-server and peer-to-peer architectures have their own advantages and are suitable for different types of networks and applications. Understanding these concepts helps in designing and implementing network solutions that best fit the specific requirements and goals of an organization or individual users.
IP Address, Subnet Mask, Gateway, MAC Address, Internet, Intranet, Extranet
Understanding the concepts of IP address, subnet mask, gateway, MAC address, Internet, intranet, and extranet is essential in the world of computer networks and connectivity. Let's explore each of these concepts:
1. IP Address:
An IP (internet Protocol) address is a unique numerical identifier assigned to each device connected to a network. It enables devices to communicate and identify each other on an IP-based network, such as the Internet or a local area network (LAN). IP addresses can be either IPv4 (32-bit) or IPv6 (128-bit) and are typically represented as a series of four or eight groups of numbers, respectively.
2. Subnet Mask:
A subnet mask is a 32-bit value used to divide an IP address into network and host portions. It determines which part of the IP address represents the network and which part represents the host. The subnet mask is used in conjunction with the IP address to identify the network to which a device belongs.
3. Gateway:
A gateway, also known as a default gateway, is a network node or device that serves as an access point or entrance to another network. It acts as an intermediary between devices on a local network and devices on external networks, such as the Internet. The gateway is responsible for routing network traffic between different networks, allowing devices to communicate with resources outside their own network.
4. MAC Address:
A MAC (Media Access Control) address is a unique identifier assigned to the network interface card (NIC) of a device. It is a hardware address that is permanently assigned by the manufacturer and is used to identify a device on a local network. MAC addresses are typically represented as a series of six pairs of hexadecimal digits (e.g., 00:1A:2B:3C:4D:5E).
5. Internet:
The Internet is a global network of interconnected networks that allows devices and computers worldwide to communicate with each other. It is a public network that provides access to a vast range of resources, services, and information available on websites, email servers, file servers, and other online platforms.
6. Intranet:
An intranet is a private network within an organization that uses Internet protocols and technologies to facilitate internal communication, collaboration, and information sharing. It is accessible only to authorized users within the organization and is used for internal purposes such as sharing documents, company resources, and internal communication.
7. Extranet:
An extranet is a controlled private network that extends beyond the boundaries of an organization to include external users, such as business partners, suppliers, or customers. It allows authorized external entities to access specific resources, collaborate, and exchange information with the organization in a secure manner.
These concepts form the foundation of network connectivity and play crucial roles in ensuring effective communication and data transfer between devices and networks.
Network Tools: Packet Tracer and Remote Login
Network tools are essential for managing and troubleshooting computer networks. Two commonly used network tools are Packet Tracer and Remote Login. Let's understand their functionalities:
1. Packet Tracer:
Packet Tracer is a network simulation tool developed by Cisco Systems. It provides a virtual environment for designing, configuring, and simulating network setups. With Packet Tracer, network administrators and students can create network topologies, configure network devices, and simulate network traffic to test various scenarios. It is widely used for learning and practicing networking concepts, as well as for troubleshooting network issues in a safe virtual environment.
2. Remote Login:
Remote login, also known as remote access or remote desktop, is a network tool that allows users to connect to and control a remote computer or server over a network connection. It enables users to access resources, applications, and files on a remote system as if they were physically present at the remote location. Remote login is particularly useful for system administrators who need to manage and troubleshoot remote computers or servers without being physically present at the location. It facilitates remote administration, support, and collaboration, saving time and effort in accessing and managing remote systems.
Both Packet Tracer and Remote Login are valuable tools in the field of networking, providing capabilities for network simulation and remote access, respectively. They enhance network management, troubleshooting, and learning experiences, contributing to efficient network operations and administration.
NIC, Modem, Router, Switch
Networking devices play a crucial role in connecting and facilitating communication between devices within a computer network. Let's explore the functions of four essential networking devices: NIC, modem, router, and switch.
1. NIC (Network Interface Card):
A Network Interface Card (NIC), also known as a network adapter, is a hardware component that enables a device to connect to a network. It provides the physical interface between a device, such as a computer or a server, and the network medium, such as Ethernet cables or wireless signals. The NIC converts data from the device into a format that can be transmitted over the network and vice versa. It typically has a unique MAC address assigned to it, which serves as its identifier on the network.
2. Modem:
A modem (modulator-demodulator) is a device that allows devices to transmit and receive data over different communication channels. In the context of networking, a modem is primarily used to connect to the Internet. It converts digital signals from a device into analog signals that can be transmitted over telephone lines, cable lines, or fiber optic lines. The modem at the receiving end then converts the analog signals back into digital signals for the receiving device to understand. Modems are commonly used for broadband Internet connections, such as DSL (Digital Subscriber Line) or cable Internet.
3. Router:
A router is a networking device that forwards data packets between different networks. It acts as a central hub and enables communication between devices on different networks, such as local area networks (LANs) or wide area networks (WANs). Routers use IP addresses to determine the most efficient path for data transmission and can make decisions based on network protocols, such as TCP/IP. They play a critical role in directing network traffic, ensuring data reaches its intended destination, and implementing network security features, such as firewall protection.
4. Switch:
A switch is a networking device that connects multiple devices within a local network. It operates at the data link layer (Layer 2) of the OSI model and uses MAC addresses to forward data packets to the correct destination. Switches create a network segment, allowing devices to communicate with each other within the same network. They provide dedicated bandwidth to each connected device, resulting in faster and more efficient data transfer compared to shared network connections. Switches are commonly used in LAN environments to connect computers, printers, servers, and other network devices.
These networking devices, including NICs, modems, routers, and switches, form the backbone of computer networks, enabling connectivity, data transmission, and efficient communication between devices.
Bus, Ring, and Star Topology
Network topology refers to the physical or logical layout of devices and connections in a computer network. Let's explore three commonly used network topologies: bus, ring, and star.
1. Bus Topology:
In a bus topology, devices in a network are connected to a single communication line, known as a bus. The bus serves as a shared communication medium that all devices on the network can access. Each device connects to the bus using a drop line or a tap. Data transmitted by any device is received by all devices on the bus, but only the intended recipient processes the data. Bus topology is relatively simple and cost-effective, but a single break in the bus can disrupt the entire network.
| Advantages | Disadvantages |
|---|---|
| - Easy to install and maintain | - Difficult to troubleshoot and locate faults |
| - Requires less cabling | - Limited scalability |
| - Cost-effective for small networks | - Performance can be affected with heavy network traffic |
2. Ring Topology:
In a ring topology, devices are connected in a closed loop, forming a ring-like structure. Each device is connected to two neighboring devices, and data circulates in one direction around the ring. When a device receives data, it processes and forwards it to the next device until it reaches the intended recipient. Ring topology provides equal access to all devices and can be implemented using physical connections or logical connections. However, the failure of a single device or link in the ring can disrupt the entire network.
| Advantages | Disadvantages |
|---|---|
| - Equal access for all devices | - Failure of a single device can disrupt the entire network |
| - Data transmission without collisions | - Difficult to add or remove devices without disrupting the network |
| - Simple and easy to implement | - Limited scalability |
3. Star Topology:
In a star topology, devices in a network are connected to a central device, such as a hub or a switch. Each device has a dedicated connection to the central device, forming a star-like structure. All data transmitted between devices passes through the central device, which manages and directs the data traffic. Star topology provides better scalability, easy troubleshooting, and the ability to add or remove devices without affecting the entire network. However, the failure of the central device can result in the entire network being disconnected.
| Advantages | Disadvantages |
|---|---|
| - Easy to add or remove devices | - Dependency on the central device |
| - Centralized management and control | - Requires more cabling compared to other topologies |
| - Fault isolation and easy troubleshooting |
These network topologies, including bus, ring, and star, offer different advantages and considerations based on the specific needs and requirements of a network.
OSI Reference Model
The OSI (Open Systems Interconnection) Reference Model is a conceptual framework that standardizes the functions of a communication system into seven different layers. Each layer in the OSI model has specific responsibilities and interacts with the adjacent layers to facilitate the exchange of data between networked devices. The layers of the OSI Reference Model are as follows:
The OSI Reference Model serves as a guideline for developing and understanding network protocols and provides a standardized framework for interoperability between different network technologies.
Internet Protocol Addressing
In computer networks, an Internet Protocol (IP) address is a unique numerical identifier assigned to each device connected to a network that uses the Internet Protocol for communication. IP addressing enables devices to send and receive data across the internet and other networks.
IP addresses are divided into two main versions: IPv4 (internet Protocol version 4) and IPv6 (internet Protocol version 6).
IPv4 addresses are 32-bit addresses expressed in dotted-decimal notation, such as 192.168.0.1. An IPv4 address consists of four sets of numbers ranging from 0 to 255, separated by periods. This format allows for approximately 4.3 billion unique addresses.
IPv4 addresses are further categorized into different classes: Class A, Class B, Class C, Class D, and Class E. Classes A, B, and C are commonly used for assigning addresses to devices in networks.
IPv6 addresses are 128-bit addresses expressed in hexadecimal notation, such as 2001:0db8:85a3:0000:0000:8a2e:0370:7334. An IPv6 address consists of eight sets of four hexadecimal digits separated by colons. This format allows for an enormous number of unique addresses, ensuring the scalability of the internet as more devices are connected.
IPv6 addresses also introduce the concept of address types, including unicast, multicast, and anycast addresses, which serve different purposes in network communication.
IP addressing provides a foundation for routing and forwarding data packets across networks. It allows devices to identify each other and establish communication over the internet and other interconnected networks.
Introduction to Web Technology
Web technology refers to the technologies and systems that are used to facilitate communication and interaction on the World Wide Web. It encompasses a wide range of technologies, protocols, and standards that enable the functioning of websites, web applications, and other internet-based services.
Here are some key components of web technology:
HTML is the standard markup language used for creating web pages. It defines the structure and content of a web page using tags and elements, allowing the browser to render and display the page's layout and components.
CSS is a style sheet language used to define the visual appearance and formatting of HTML documents. It enables web developers to specify the colors, layouts, fonts, and other visual aspects of a web page, enhancing its aesthetics and user experience.
JavaScript is a programming language that enables dynamic and interactive behavior on web pages. It allows developers to add interactivity, perform client-side validations, manipulate web page content, and create rich user experiences.
Web servers are software applications or computer systems that deliver web content to clients upon request. They store and serve web pages, process user requests, handle data retrieval from databases, and facilitate communication between clients and servers.
Web browsers are applications that allow users to access and view web pages on the internet. They interpret HTML, CSS, and JavaScript code and render web content, enabling users to navigate websites, interact with web applications, and consume online information.
Web development frameworks and libraries provide pre-built tools, components, and functionalities that simplify the process of web application development. Examples include React, Angular, and Django, which offer reusable code, MVC (Model-View-Controller) architecture, and other features to expedite development.
Web technology continues to evolve, introducing new standards, protocols, and techniques to enhance web experiences, improve performance, and ensure security. It has revolutionized how information is accessed, shared, and communicated, shaping the modern digital landscape.
Server-Side and Client-Side Scripting
Server-side scripting and client-side scripting are two approaches to executing scripts in web development, each serving different purposes and functioning on different sides of the web architecture.
Server-side scripting refers to the execution of scripts on the server before the web page is sent to the client's browser. It involves processing and generating dynamic content on the server side, which is then delivered to the client as a static HTML page. Common server-side scripting languages include PHP, Python, Ruby, and Java.
Here are some key characteristics and uses of server-side scripting:
Client-side scripting refers to the execution of scripts on the client's browser after receiving the web page from the server. The scripts are typically embedded within the HTML code and are executed by the client's browser. JavaScript is the primary language used for client-side scripting.
Here are some key characteristics and uses of client-side scripting:
Both server-side and client-side scripting play integral roles in web development, working together to deliver dynamic and interactive web experiences to users.
Adding JavaScript to HTML Page
JavaScript is a widely used programming language for adding interactivity and dynamic behavior to HTML pages. To incorporate JavaScript into an HTML page, follow these steps:
Create a new HTML file or open an existing one in a text editor or an integrated development environment (IDE).
 Tag
TagWithin the<head>or<body>section of your HTML file, add the<script>tag to define the JavaScript code. There are two main ways to include JavaScript code:
<script>tag. For example: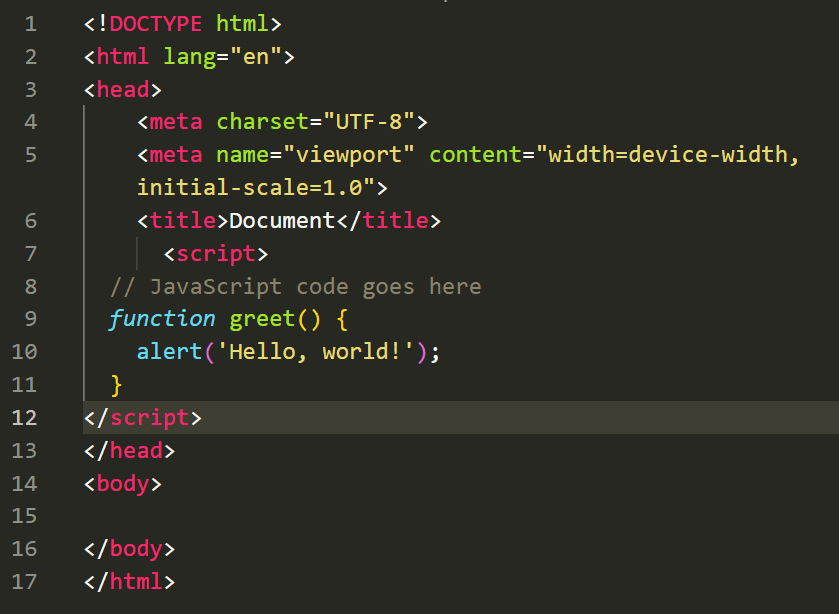
srcattribute of the<script>tag. For example: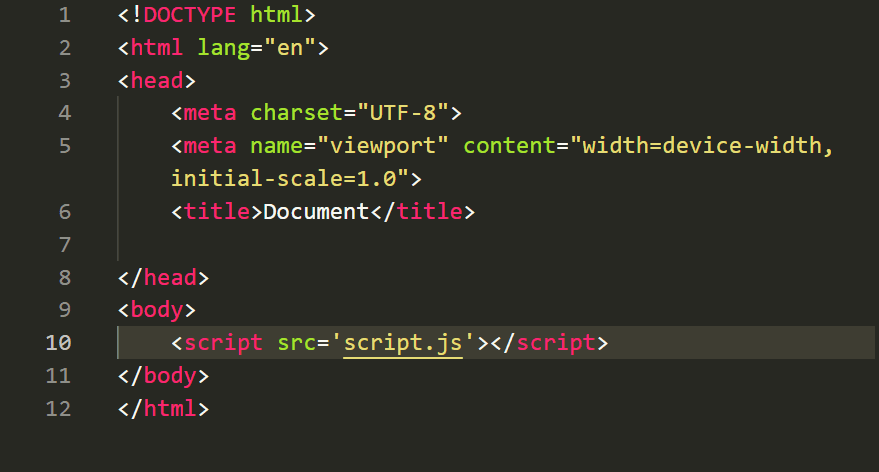
In this case, the JavaScript code is stored in a separate file named 'script.js' in the same directory as the HTML file.
Within the<script>tags, write your JavaScript code. You can define functions, variables, manipulate the DOM, and add interactivity to your web page.
You can use JavaScript to interact with HTML elements by referencing them using their IDs, classes, or tags. For example, you can use JavaScript to change the text of an HTML element:
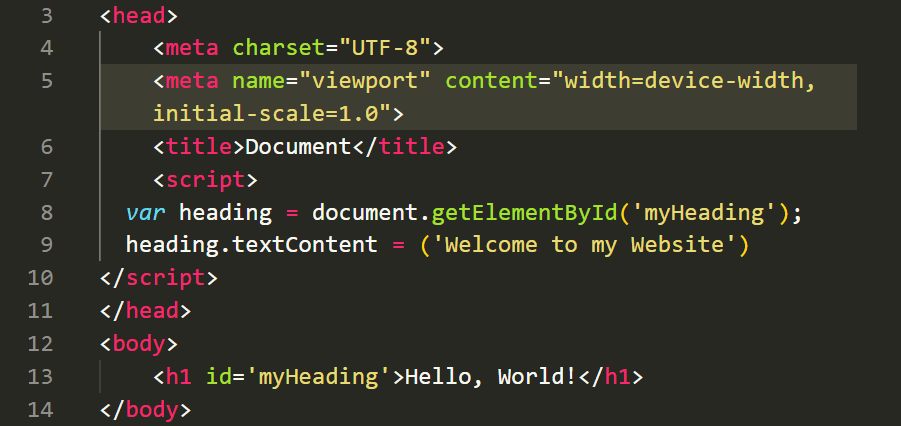
By manipulating HTML elements using JavaScript, you can create dynamic and interactive web pages.
Save the HTML file with a .html extension and open it in a web browser. The browser will interpret the JavaScript code and execute it, resulting in the expected behavior on the web page.
Remember to place the <script>tag appropriately within the HTML structure to ensure proper execution of the JavaScript code.
That's it! You have successfully added JavaScript to your HTML page and can now enhance its interactivity and functionality.
JavaScript Fundamentals
JavaScript is a versatile programming language that enables you to add interactivity and dynamic behavior to web pages. Here are some fundamental concepts of JavaScript:
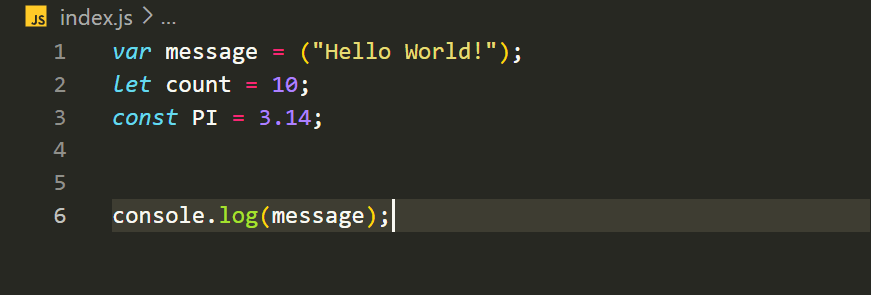
Variables in JavaScript are used to store and manipulate data. You can declare variables using thevar,let, orconstkeywords. For example:
JavaScript supports various data types, including:
JavaScript provides various operators for performing operations on variables and values. Some common operators include:
JavaScript allows you to control the flow of execution using conditional statements (if/else, switch) and loops (for, while, do-while). These control flow structures help you make decisions and repeat actions based on certain conditions.
Functions in JavaScript are reusable blocks of code that perform specific tasks. You can define functions and call them to execute their code. Functions can take parameters and return values. For example:
.png&w=3840&q=75)
The Document Object Model (DOM) allows JavaScript to interact with HTML elements on a web page. You can access, modify, and manipulate HTML elements using JavaScript to create dynamic and interactive web experiences.
JavaScript can respond to user actions and events on a web page. You can attach event handlers to HTML elements to trigger specific JavaScript code when events occur, such as button clicks, form submissions, or mouse movements.
These are just some of the fundamental concepts of JavaScript. By understanding and applying these concepts, you can begin to build interactive and engaging web applications.
JavaScript Data Types
JavaScript supports various data types that allow you to work with different kinds of values. Here are the commonly used data types in JavaScript:
TheNumberdata type represents numeric values. It can store both integers and floating-point numbers. For example:

TheStringdata type represents textual data. It is used to store sequences of characters, enclosed in single or double quotes. For example:

TheBooleandata type represents logical values:trueorfalse. It is often used in conditional statements and logical operations. For example:

TheArraydata type is used to store multiple values in a single variable. It is represented by square brackets and can hold values of different types. For example:
TheObjectdata type allows you to create custom data structures by grouping related data and functionality together. It is represented by curly braces and consists of key-value pairs. For example:

Thenullandundefineddata types represent the absence of value or the absence of an assigned value, respectively.nullis used when you want to explicitly indicate that a variable has no value, whileundefinedis the default value for uninitialized variables. For example:
var data = null;var value;These are the fundamental data types in JavaScript. Understanding these data types is crucial for working with variables, manipulating data, and performing operations in JavaScript.
Variables and Operators in JavaScript
In JavaScript, variables are used to store and manipulate data. Operators, on the other hand, are used to perform various operations on data. Let's explore variables and operators in JavaScript:
Variables are containers for storing data values. In JavaScript, you can declare variables using thevar,let, orconstkeywords. Here's an example:
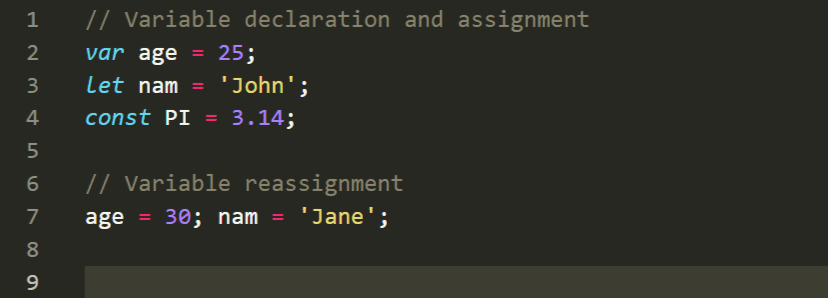
In the above example, we declare variablesage,name, andPIand assign values to them. Thevarkeyword allows variable reassignment, whileletandconstprovide block-scoping and prevent reassignment, respectively.
JavaScript supports various operators for performing operations on data. Here are some commonly used operators:
Arithmetic operators are used to perform mathematical calculations. Examples include:
+(addition)-(subtraction)*(multiplication)/(division)%(modulus)Assignment operators are used to assign values to variables. Examples include:
=(simple assignment)+=(addition assignment)-=(subtraction assignment)*=(multiplication assignment)/=(division assignment)Comparison operators are used to compare values. They returntrueorfalsebased on the comparison result. Examples include:
==(equal to)!=(not equal to)>(greater than)<(less than)>=(greater than or equal to)<=(less than or equal to)Logical operators are used to combine and manipulate logical values. Examples include:
&&(logical AND)||(logical OR)!(logical NOT)These are just a few examples of the operators available in JavaScript. They allow you to perform operations, make decisions, and manipulate data in your JavaScript code.
Functions and Control Structures in JavaScript
In JavaScript, functions and control structures are used to control the flow of execution and perform repetitive tasks. Let's explore some commonly used control structures:
Functions in JavaScript allow you to encapsulate a block of code and execute it whenever needed. They can take input parameters, perform operations, and return a value. Here's an example of defining and calling a function:
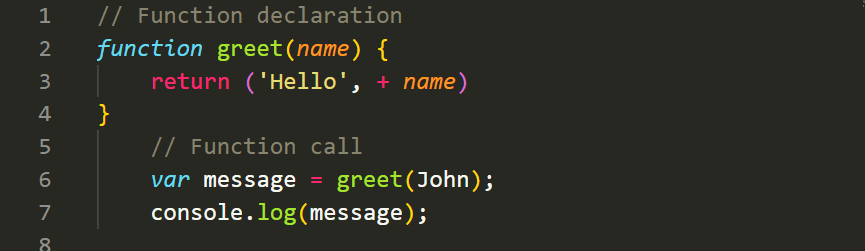
In the above example, we define a function calledgreetthat takes anameparameter and returns a greeting message. We then call the function and store the returned value in themessagevariable.
Control structures in JavaScript allow you to control the flow of execution based on certain conditions or perform repetitive tasks. Here are some commonly used control structures:
The if-else statement allows you to execute different blocks of code based on a specified condition. Here's an example:

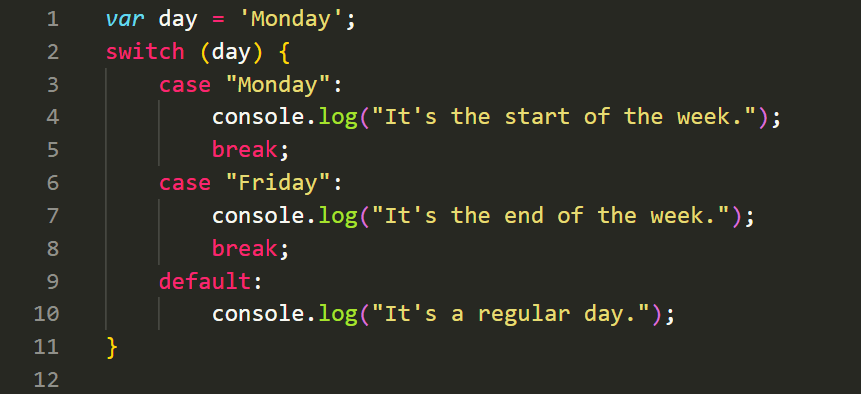
The switch-case statement allows you to perform different actions based on different cases. It is often used when you have multiple conditions to check. Here's an example:
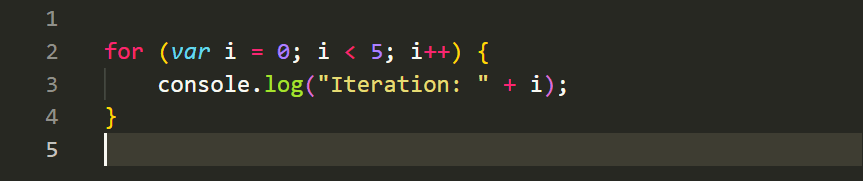
The for loop is used to execute a block of code a specified number of times. It typically includes an initialization, a condition, and an increment/decrement. Here's an example:
The while loop is used to repeatedly execute a block of code as long as a specified condition is true. Here's an example:

The do-while loop is similar to the while loop, but it guarantees that the code block is executed at least once, even if the condition is initially false. Here's an example:

These are some of the fundamental control structures in JavaScript that allow you to perform conditional checks and repetitive tasks in your code.
Object-Based Programming with JavaScript and Event Handling
JavaScript is an object-based programming language, which means it revolves around objects and their interactions. Objects in JavaScript are collections of properties and methods that represent entities or concepts. Let's explore object-based programming and event handling in JavaScript:
In JavaScript, you can create objects using object literals or constructor functions. Object literals allow you to define an object and its properties and methods directly. Here's an example:
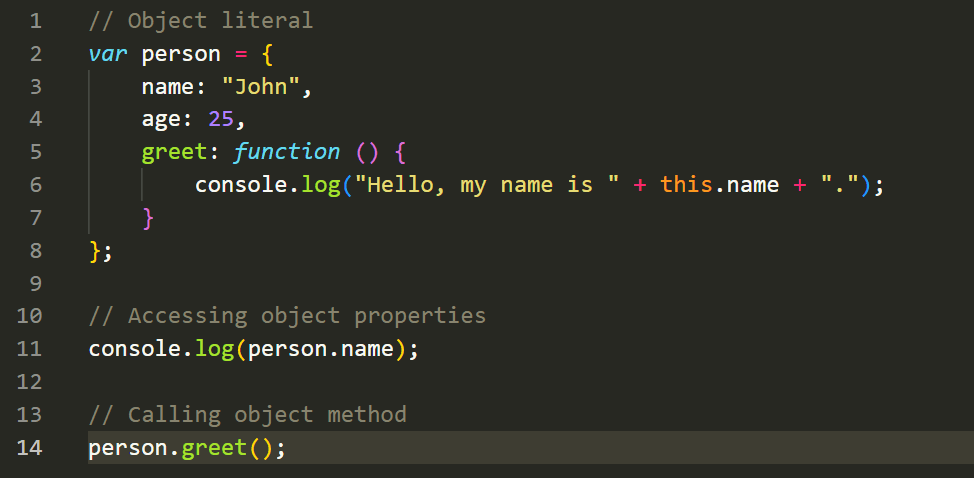
In the above example, we create an object calledpersonusing an object literal. It has properties likenameandage, as well as a method calledgreetthat logs a greeting message using thenameproperty.
Event handling is a crucial aspect of web development that allows you to respond to user actions or system events. In JavaScript, you can handle events using event listeners. Here's an example of handling a button click event:
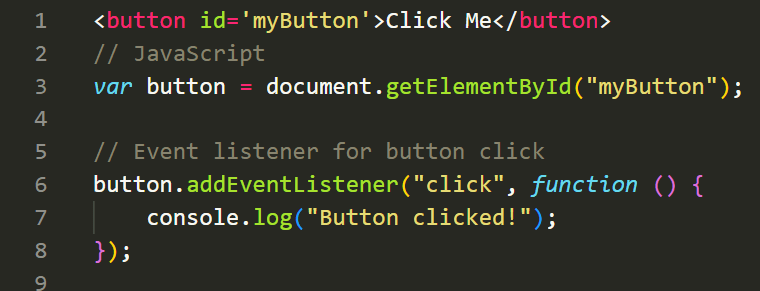
In the above example, we retrieve a reference to the button element using its ID. We then attach an event listener to the button for theclickevent. When the button is clicked, the associated callback function is executed, which logs a message to the console.
Event handling allows you to make your web pages interactive and responsive by executing specific actions based on user interactions or system events.
Image, Event, and Form Objects in JavaScript
JavaScript provides various built-in objects that allow you to work with different aspects of web development, including handling images, events, and forms. Let's explore these objects:
The Image object in JavaScript represents an HTML<img>element. It allows you to load and manipulate images dynamically on your web page. Here's an example:
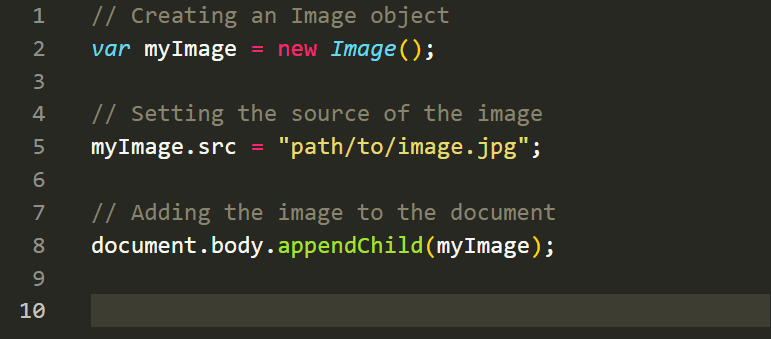
In the above example, we create an Image object using thenew Image()constructor. We set the source of the image using thesrcproperty and then append the image to the document usingappendChild().
The Event object represents an event that occurs in the browser, such as a mouse click, keyboard input, or form submission. It provides information and methods related to the event. Here's an example of event handling:
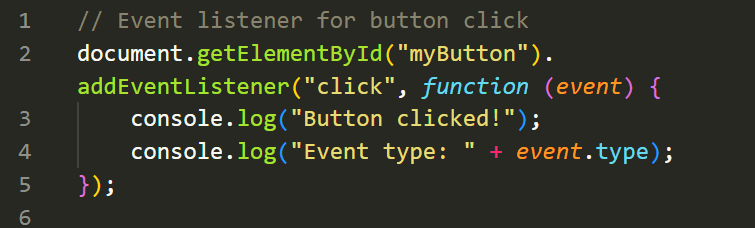
In the above example, we attach an event listener to a button's click event. The associated callback function receives the Event object as a parameter, which allows us to access information about the event. In this case, we log the event type, which will be 'click'.
The Form object represents an HTML<form>element and provides methods and properties to work with form controls and perform form-related operations. Here's an example:
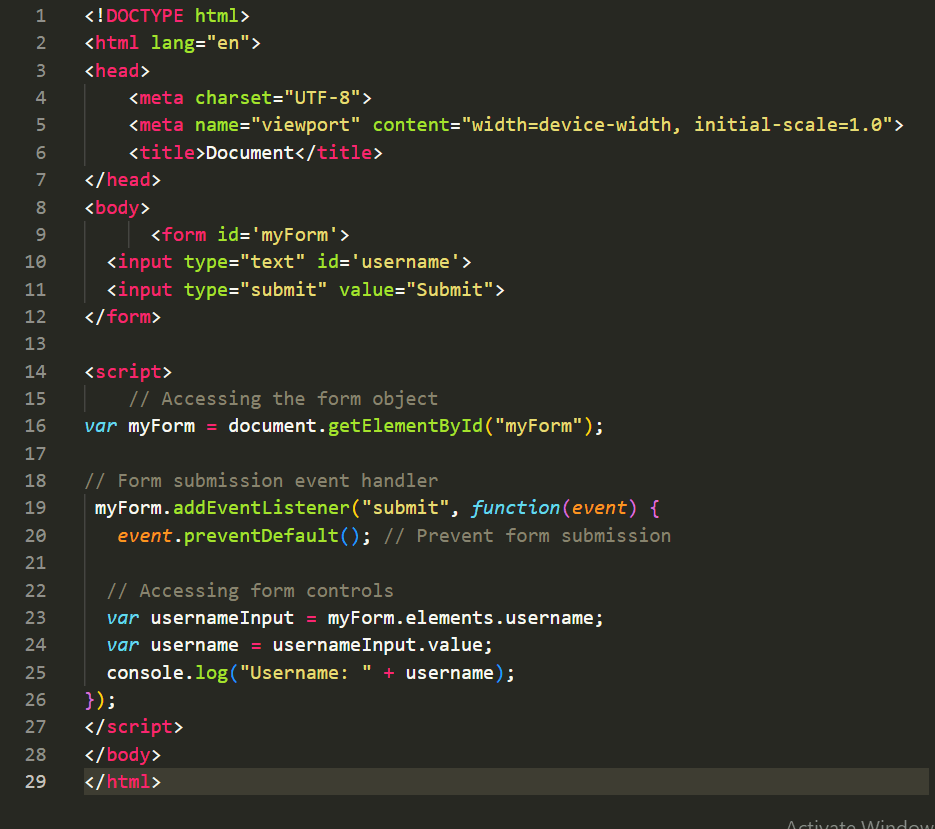
In the above example, we retrieve a reference to the form element using its ID. We attach an event listener to the form's submit event and prevent the default form submission using.png&w=3840&q=75) . We access the form controls using the
. We access the form controls using theelementsproperty and retrieve the value of the username input field.
These objects - Image, Event, and Form - provide powerful capabilities to work with images, handle events, and manipulate form data in JavaScript, allowing you to create interactive and dynamic web applications.
Form Validation and jQuery
Form validation is an essential part of web development to ensure that user input meets certain criteria or constraints. JavaScript can be used to perform form validation, but jQuery, a popular JavaScript library, provides a simplified and efficient way to handle form validation tasks. Let's explore form validation and how jQuery can be used for this purpose:
Form validation with JavaScript involves writing custom JavaScript code to check the form input and display appropriate error messages if the input is invalid. Here's an example of form validation using JavaScript:

In the above example, the form has anonsubmitattribute that calls thevalidateForm()function when the form is submitted. The function retrieves the values of the name and email fields and performs validation checks. If any validation check fails, an alert is displayed, and the function returnsfalseto prevent form submission.
jQuery simplifies form validation by providing ready-to-use methods and functions. It allows you to select form elements easily and apply validation rules using its built-in validation plugin. Here's an example of form validation using jQuery:
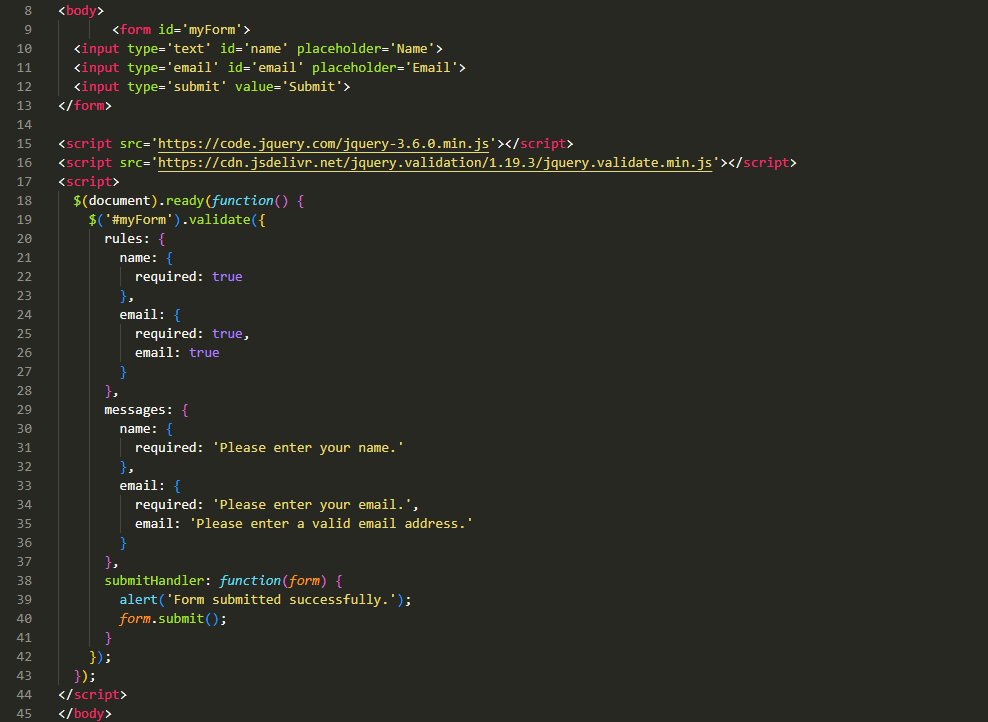
In the above example, we include the jQuery library and the jQuery Validation plugin using their respective script tags. We use thevalidate()method to apply form validation rules. Therulesobject specifies the validation rules for each form field, while themessagesobject defines custom error messages. ThesubmitHandlerfunction is called when the form is submitted successfully, allowing you to perform additional actions, such as displaying a success message or submitting the form.
Using jQuery for form validation reduces the amount of custom JavaScript code needed and provides a more concise and standardized approach.
Operators in PHP
Arithmetic Operators:
Assignment Operators:
Comparison Operators:
Logical Operators:
These are just a few examples of operators in PHP. There are more operators available in PHP for different purposes, such as bitwise operators, increment/decrement operators, and ternary operators. Operators are essential for performing various operations and comparisons in PHP programming.
Variable Manipulation in PHP
In PHP, variables are used to store and manipulate data. Variable manipulation involves performing operations on variables to modify their values, concatenate strings, convert data types, and more. Here are some common variable manipulation techniques in PHP:
1. Assignment:
Assigning a value to a variable is done using the assignment operator (=). For example:
2. Concatenation:
Concatenation is the process of combining strings. In PHP, the concatenation operator (.) is used. For example:
3. Variable Interpolation:
Variable interpolation allows variables to be directly embedded within double-quoted strings. For example:
4. Type Conversion:
PHP automatically converts data types as needed, but explicit type conversion can also be performed using typecasting. For example:
5. Increment and Decrement:
PHP provides shorthand operators for incrementing and decrementing variables. For example:
6. Variable Swapping:
Variable values can be swapped using a temporary variable or by leveraging the list() function. For example:
These are some of the common techniques for manipulating variables in PHP. Understanding and utilizing these techniques will help you effectively work with data and perform various operations in PHP programming.
Functions in C
In the C programming language, functions are used to encapsulate a set of statements that perform a specific task. Functions provide modularity and code reusability by allowing you to divide your program into smaller, manageable pieces. Here's an overview of functions in C:
Function Declaration:
In C, a function must be declared before it is used. The declaration specifies the function's return type, name, and any parameters it accepts. For example:
Function Definition:
The function definition contains the actual implementation of the function. It includes the function's return type, name, parameter list, and the statements that define its behavior. For example:
Function Call:
To use a function in C, you need to call it by its name and provide the necessary arguments. The function call may also assign the return value to a variable or use it directly. For example:
Function Return Type:
A function in C can have a return type, which indicates the type of value the function will return after execution. It can be a built-in type or a user-defined type. If a function does not return any value, its return type is declared asvoid. For example:

Function Parameters:
Parameters are variables declared in the function declaration and definition that receive values from the calling code. Functions can have zero or more parameters, and each parameter has a type and a name. For example:
Function Prototypes:
A function prototype declares the function's signature (return type, name, and parameter types) without providing the function definition. It allows you to use a function before defining it. For example:
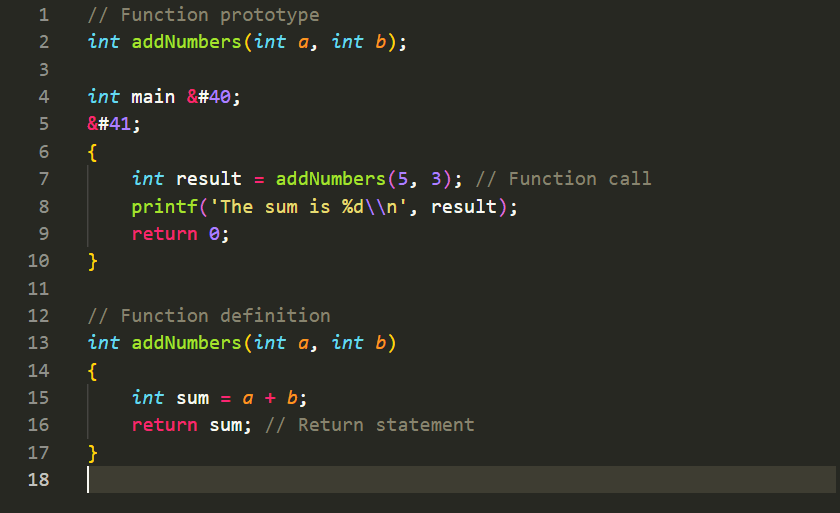
These are some fundamental concepts related to functions in the C programming language. Functions play a vital role in structuring and organizing code, making it easier to develop and maintain complex programs.
Library Functions and User-Defined Functions in C
Library Functions:
Library functions, also known as built-in functions, are pre-defined functions provided by the C standard library or other libraries. These functions are already implemented and available for use in C programs without the need for additional coding. Library functions offer a wide range of functionality, such as performing mathematical operations, manipulating strings, input/output operations, memory management, and more. Examples of library functions in C include . Library functions help simplify programming tasks and provide efficient solutions for common operations.
. Library functions help simplify programming tasks and provide efficient solutions for common operations.
User-Defined Functions:
User-defined functions are functions created by the programmer to perform specific tasks based on their requirements. These functions are implemented and customized by the user according to the logic and functionality needed in the program. User-defined functions can be declared and defined in the C program, providing a modular and structured approach to programming. By encapsulating specific functionality within user-defined functions, the main program can be more readable, maintainable, and easier to debug. User-defined functions can be created to perform repetitive tasks, complex calculations, or any specific functionality not provided by the built-in library functions.
Advantages of Library Functions:
Advantages of User-Defined Functions:
Combining the use of library functions and user-defined functions provides a powerful approach to C programming. Library functions offer a wide range of functionality, while user-defined functions provide flexibility, code organization, and customization to meet specific programming needs.
Function Definition, Prototype, Call, and Return Statements in C
In C programming, functions are defined, prototyped, called, and include return statements to control program flow and perform specific tasks. Here's an explanation of these concepts:
Function Definition:
A function definition contains the actual implementation of the function. It includes the function's return type, name, parameter list, and the statements that define its behavior. The syntax for a function definition is as follows:
Function Prototype:
A function prototype declares the function's signature (return type, name, and parameter types) without providing the function definition. It serves as a forward declaration of the function, allowing the program to know about the function before using it. The syntax for a function prototype is as follows:
Function Call:
To use a function in C, you need to call it by its name and provide the necessary arguments. The function call statement invokes the function and executes the statements inside it. The syntax for a function call is as follows:
Return Statement:
The return statement is used to terminate a function and return a value to the calling code. It specifies the value to be returned and control is transferred back to the calling code. The syntax for a return statement is as follows:
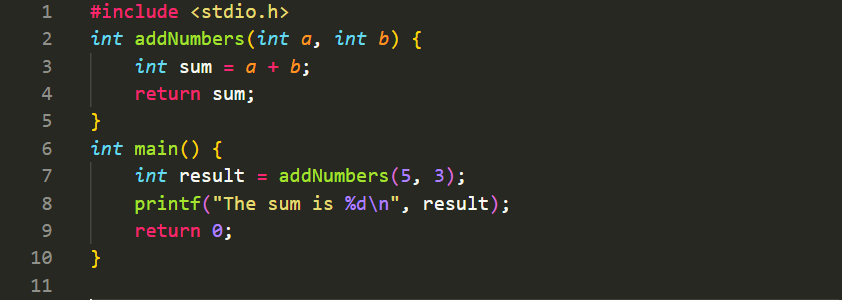
Here's an example that demonstrates these concepts:
In this example, the functionaddNumbers()is defined, prototyped, called, and includes a return statement. The function prototype informs the compiler about the function's existence before themain()function is called. The function call statement inmain()invokes theaddNumbers()function and passes the arguments5and3. Inside theaddNumbers()function, the sum of the two numbers is calculated, and the result is returned using the return statement. The returned value is then assigned to the variableresultin themain()function and displayed usingprintf().
Understanding and utilizing these concepts enables you to create and use functions effectively in your C programs, providing modularity, reusability, and control over program execution.
Accessing a function by passing values:
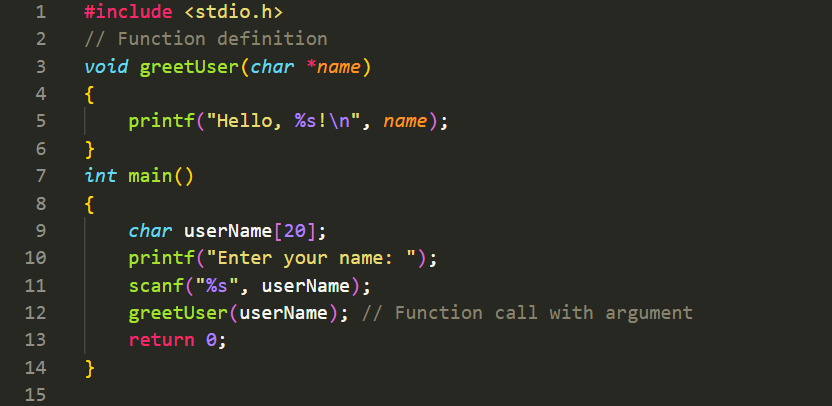
Concept of Storage: Automatic and External
In C programming, storage refers to the memory space allocated to variables and functions during program execution. There are two primary storage classes in C: automatic and external. Let's explore these concepts:
Automatic Storage:
Automatic storage refers to the memory allocated for variables defined within a function or block. These variables have automatic storage duration, meaning they are created when the block is entered and destroyed when the block is exited. Automatic variables are typically declared using the \`auto\` keyword, although it is optional since it is the default storage class. For example:
The automatic variable \`num\` is allocated memory when \`myFunction()\` is called and released when the function returns or exits the block.
External Storage:
External storage refers to the memory allocated for variables declared outside of any function or block. These variables have external storage duration, meaning they exist throughout the entire program execution. External variables are typically declared using the \`extern\` keyword, indicating that the variable is defined elsewhere. For example:
In this example, the \`globalVar\` variable is declared as an external variable using the \`extern\` keyword. It is defined in another source file or library and can be accessed by multiple functions within the program.
It's worth noting that the \`extern\` keyword is used for declaring external variables, while the actual definition is provided outside any function or block.
The concept of storage in C provides flexibility in managing memory for variables and functions. Automatic storage is suitable for temporary variables within a limited scope, while external storage allows for sharing variables across different functions or files.
Concept of Recursion: Factorial and Fibonacci Problems
Recursion is a programming technique where a function calls itself repeatedly to solve a problem by breaking it down into smaller subproblems. It involves defining a base case that terminates the recursive process and one or more recursive cases that reduce the problem towards the base case. Let's explore the concept of recursion with two classic examples: factorial and Fibonacci sequence.
Factorial:
The factorial of a non-negative integer n, denoted as n!, is the product of all positive integers from 1 to n. The factorial function can be defined recursively as follows:
In the factorial function, the base case is when n is 0 or 1, where the function returns 1. In the recursive case, the function multiplies n with the factorial of (n-1) until the base case is reached. This recursion continues until the desired factorial value is computed.
Fibonacci Sequence:
The Fibonacci sequence is a series of numbers in which each number (after the first two) is the sum of the two preceding ones. The Fibonacci sequence can be defined recursively as follows:
In the Fibonacci function, the base cases are when n is 0 and 1, where the function returns 0 and 1, respectively. In the recursive case, the function calculates the Fibonacci of n by summing the Fibonacci of (n-1) and Fibonacci of (n-2) until the base cases are reached.
Recursion provides an elegant way to solve problems that can be divided into smaller subproblems. However, it's important to handle base cases correctly to prevent infinite recursion. Understanding the concept of recursion helps in solving complex problems by breaking them down into simpler, recursive steps.
Structure: Definition, Declaration, Initialization, and Size
In C programming, a structure is a user-defined data type that allows you to group related data items together under a single name. It provides a way to create complex data structures by combining different data types into a single unit. Let's explore the concepts of structure definition, declaration, initialization, and size:
Structure Definition:
A structure is defined using the \`struct\` keyword followed by the structure name and a list of member variables enclosed in curly braces. The structure definition does not allocate memory for the structure but provides a blueprint for creating instances of the structure. For example:
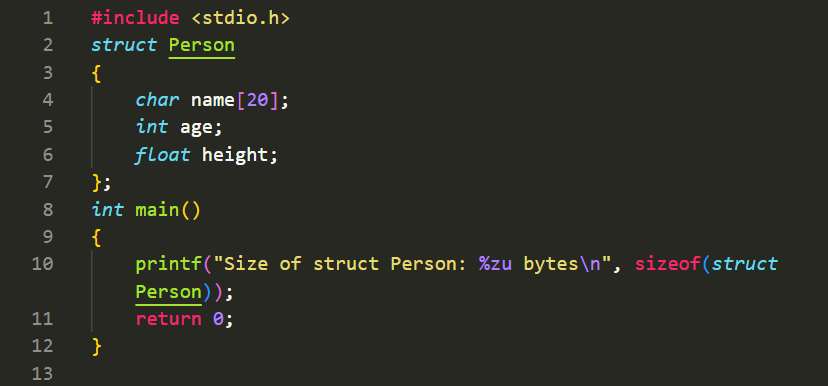
In this example, we define a structure named \`Person\` with three member variables: \`name\` of type \`char\` array, \`age\` of type \`int\`, and \`height\` of type \`float\`. The structure definition specifies the layout and data types of the structure members.
Structure Declaration:
Structure declaration creates variables of the structure type. To declare a structure variable, you use the structure name followed by the variable name. For example:
In this case, we declare two variables of type \`Person\` named \`p1\` and \`p2\`. Each variable will have its own memory space to hold the structure members.
Structure Initialization:
Structure variables can be initialized during declaration or later using the assignment operator (\`=\`). To initialize a structure during declaration, you enclose the initial values within curly braces and provide them in the same order as the structure members. For example:
In this case, we initialize the \`p1\` structure variable with the values 'John Doe' for \`name\`, 25 for \`age\`, and 1.75 for \`height\`.
Structure Size:
The size of a structure is determined by the combined size of its members, with potential padding added for alignment purposes. The \`sizeof\` operator in C can be used to find the size of a structure in bytes. For example:
In this example, the \`sizeof\` operator is used to determine the size of the \`Person\` structure. The result is printed using \`printf()\`. The size of a structure may vary depending on the sizes of its member variables and any padding added by the compiler for alignment.
Understanding structure definition, declaration, initialization, and size allows you to define and work with complex data structures in C, organizing related data into cohesive units.
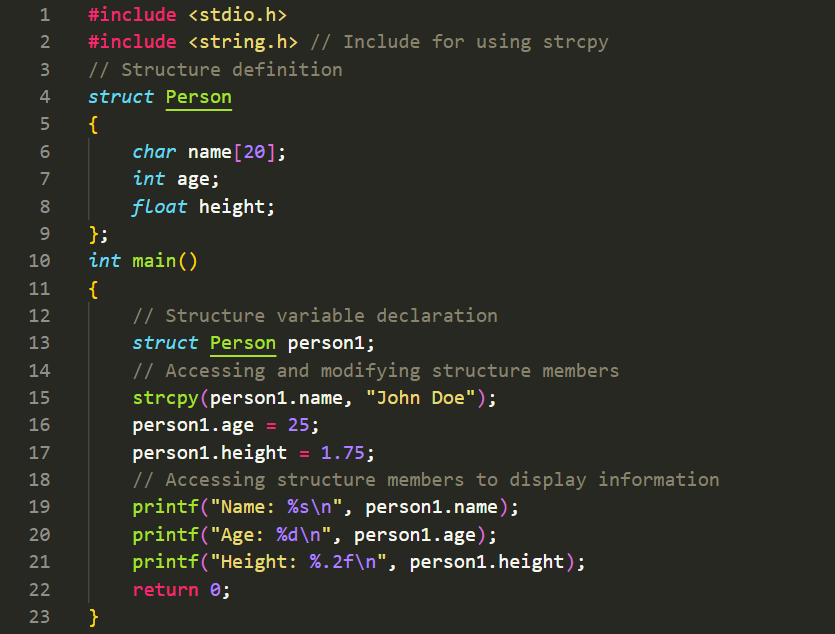
Array of Structures
In C, you can create an array of structures by combining the concept of arrays and structures. This allows you to store multiple instances of a structure in a contiguous block of memory. Each element of the array represents an individual structure. Let's see an example:

In this example, we define a structure named \`Person\` with three members: \`name\`, \`age\`, and \`height\`. Inside the \`main()\` function, we declare an array of structures named \`people\` with a size of 3. Each element of the array represents an individual \`Person\` structure.
We access and modify the members of the structures in the array using the dot operator (\`.\`). For example, \`people[0].name\` accesses the \`name\` member of the first structure in the array. Similarly, we assign values to other members of different structures in the array.
To display the information of each person in the array, we use a \`for\` loop to iterate through the array. We access the structure members using the dot operator and print their values using \`printf()\` statements.
The output of the program will display the information of each person in the array:
An array of structures allows you to work with multiple instances of a structure efficiently, storing related data in a structured manner.
Union: Definition and Declaration
In C programming, a union is a user-defined data type that allows you to store different types of data in the same memory space. Unlike structures, where each member has its own memory space, union members share the same memory location. This means that a union can hold only one value at a time.
Union Definition:
A union is defined using the \`union\` keyword followed by the union name and a list of member variables enclosed in curly braces. The members can have different data types, and they all share the same memory location. For example:
In this example, we define a union named \`Data\` with three members: \`integer\` of type \`int\`, \`floatingPoint\` of type \`float\`, and \`character\` of type \`char\`. All three members share the same memory location.
Union Declaration:
To declare a union variable, you use the union name followed by the variable name. For example:
In this case, we declare a union variable named \`value\` of type \`Data\`. The memory allocated for \`value\` can be used to store any of the members defined in the union.
After declaring a union variable, you can access the members using the dot (\`.\`) operator, similar to accessing structure members. However, remember that only one member of the union can be active at a time.
Unions are particularly useful when you want to represent different types of data using the same memory location or when you need to save memory by using a single space for multiple data types.
| Union | Structure |
|---|---|
|
|
Pointer
A pointer is a variable in C that stores the memory address of another variable. It 'points' to the location of a specific data object in memory. Pointers allow you to indirectly access and manipulate variables by referencing their memory locations rather than their values directly.
Pointers are declared by using the asterisk (*) symbol before the variable name. The type of the pointer indicates the type of the variable it points to. For example:
In this example, we declare a pointer named \`ptr\` of type \`int\`. It can store the memory address of an integer variable.
You can assign the address of a variable to a pointer by using the address-of operator (&). For example:
In this case, we assign the address of the \`num\` variable to the \`ptr\` pointer. Now, \`ptr\` points to the memory location of \`num\`.
To access the value of the variable pointed to by a pointer, you use the dereference operator (*). For example:
In this case, we assign the value stored at the memory location pointed to by \`ptr\` to the \`value\` variable.
Pointers are widely used in C programming for various purposes, including dynamic memory allocation, passing variables by reference, and working with arrays and complex data structures.
Pointer Expression and Assignment
In C programming, pointer expressions and assignments are used to manipulate and work with pointers. Let's explore how pointer expressions are formed and how assignments can be made:
Pointer Expression:
A pointer expression is an expression that involves pointers. It can be formed by using the following operators:
Pointer Assignment:
Pointer assignment is used to assign a value or address to a pointer. There are two common types of pointer assignment:
Pointer expressions and assignments are essential in C programming for tasks such as dynamic memory allocation, accessing and manipulating data through pointers, and working with complex data structures.
Call by Value and Call by Reference
In programming, 'call by value' and 'call by reference' are two different approaches for passing arguments to functions. Let's understand the differences between these two methods:
Call by Value:
In call by value, the values of the arguments are passed to the function. A copy of the values is created, and any modifications made to the parameters within the function do not affect the original values outside the function. The original variables remain unchanged.
Here's an example of a function called \`swap\` that exchanges the values of two integers:
In this case, when the \`swap\` function is called, the values of \`x\` and \`y\` are copied into the function parameters \`a\` and \`b\`. The swapping operation occurs within the function, but it does not affect the original variables \`x\` and \`y\` in the \`main\` function.
Call by Reference:
In call by reference, the memory addresses (references) of the arguments are passed to the function. Instead of working with copies, the function receives the actual memory locations of the variables. Any modifications made to the parameters within the function directly affect the original variables outside the function.
Here's an example using call by reference:
In this example, the \`swap\` function takes pointers to integers (\`int*\`) as arguments. The addresses of \`x\` and \`y\` are passed using the address-of operator (\`&\`). Within the function, the pointers are dereferenced using the asterisk (\`*\`) to access and modify the values at the memory locations.
As a result, the values of \`x\` and \`y\` in the \`main\` function are swapped because the modifications made within the \`swap\` function affect the original variables due to the use of call by reference.
Call by value is typically used when you want to keep the original values intact and avoid unintended modifications. Call by reference is useful when you want to modify the original variables within the function or pass large data structures without incurring the overhead of copying.
Data File
In computer science and programming, a data file is a collection of data that is stored and organized for efficient retrieval and manipulation. It is a structured or unstructured file that contains information in a specific format, such as text, binary, or a combination of both.
Data files are used to store various types of data, including text documents, images, audio files, videos, database records, configuration settings, and more. They serve as a persistent storage medium, allowing data to be saved and accessed even after the program or system is closed or restarted.
Data files can be categorized into different types based on their structure and format:
Data files are accessed and manipulated by programs using file input/output (I/O) operations. These operations allow data to be read from or written to the file, enabling data storage, retrieval, modification, and deletion. File I/O functions and libraries are available in various programming languages to facilitate working with data files.
Data files play a vital role in many applications and systems, enabling the persistent storage and management of data for different purposes, such as data analysis, information retrieval, data exchange, and archival.
Sequential File and Random File
In the context of data files, 'sequential file' and 'random file' refer to different methods of accessing and manipulating the data within a file. Let's understand the characteristics and differences between these two file access methods:
Sequential File:
A sequential file is a type of data file where the records are stored and accessed in a sequential manner, one after another, in a specific order. The records in a sequential file are typically stored consecutively in the file, and the file is processed from the beginning to the end in a linear fashion.
Sequential file access follows a specific sequence, starting from the first record and proceeding sequentially until the desired record is found or the end of the file is reached. This means that to access a specific record in a sequential file, all preceding records must be read and processed first.
Sequential file access is efficient for tasks that involve processing the entire file sequentially, such as batch processing or generating reports. However, it can be inefficient for random access or searching specific records within the file since it requires reading and processing all preceding records.
Random File:
A random file, also known as a direct access file or indexed file, allows direct access to individual records within the file without the need to process preceding records. In a random file, records are stored independently, and each record is associated with a unique identifier or key.
Random file access allows for direct retrieval and modification of specific records based on their keys. Instead of reading the entire file sequentially, the file system uses the provided key to locate and access the desired record directly.
Random file access is efficient when quick access to specific records is required, such as in database systems or applications that involve frequent searching, updating, or retrieval of specific data elements.
The choice between sequential and random file access depends on the nature of the application and the operations performed on the data. Sequential file access is suitable for tasks that involve processing data in a linear manner, while random file access is ideal for applications that require quick access to specific records without the need for sequential processing.
File Manipulation Functions
In programming, file manipulation functions are used to perform various operations on files, such as creating, opening, reading, writing, modifying, and closing files. These functions provide the necessary functionality to interact with files and manipulate their content. Here are some commonly used file manipulation functions:
These are just a few examples of file manipulation functions available in various programming languages. The specific functions and their usage may vary depending on the programming language and the file system being used.
Opening, Reading, Writing, and Appending Data Files
When working with data files, you typically need to perform operations such as opening the file, reading its content, writing new data, and appending data to an existing file. Let's explore how these operations are performed using file manipulation functions:
Opening a Data File:
To open a data file, you can use the fopen function. It takes two parameters: the filename (including the path) and the mode in which the file should be opened. Here are some commonly used modes:
Example:
Reading from a Data File:
To read data from a file, you can use functions such as fread or fgets. The fread function reads a specified number of elements from the file, while the fgets function reads a line of text from the file.
Example:
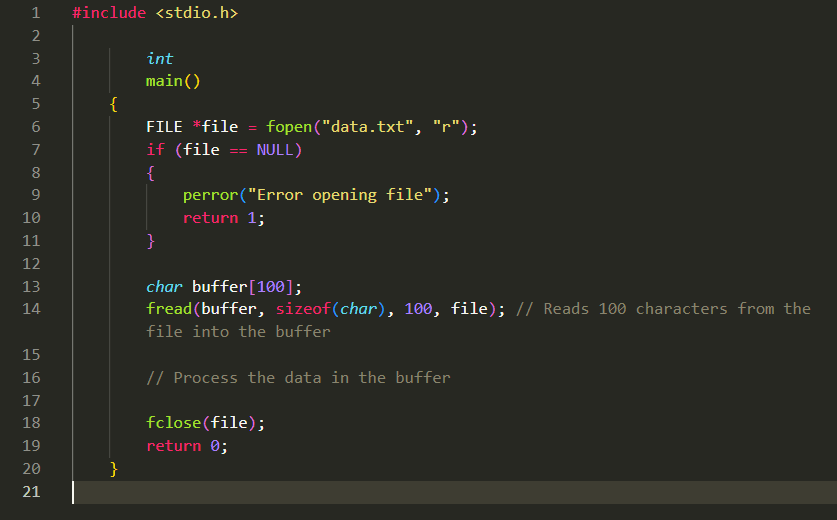
Writing to a Data File:
To write data to a file, you can use functions such as fwrite or fputs. The fwrite function writes a specified number of elements to the file, while the fputs function writes a string to the file.
Example:
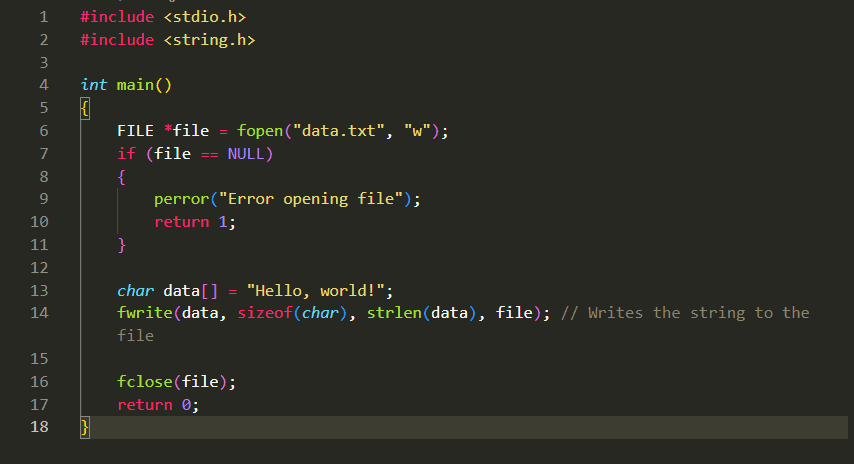
Appending to a Data File:
To append data to an existing file, you can open the file in 'a' (append) mode. Subsequent write operations will add data to the end of the file.
Example:
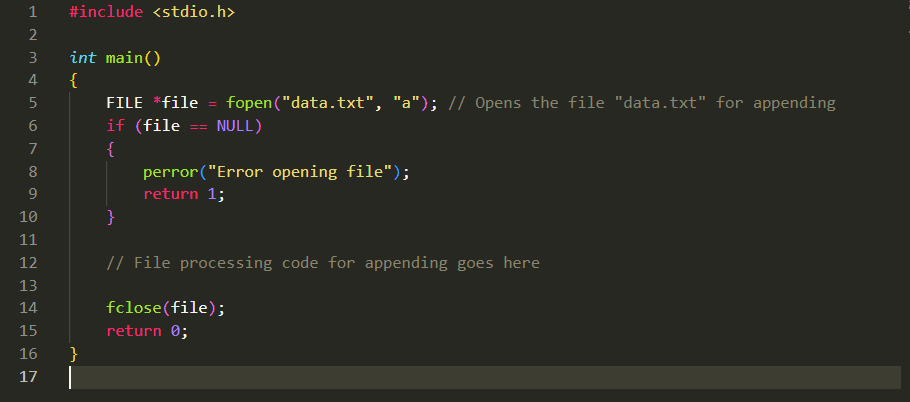
After performing the necessary operations, remember to close the file using the fclose function:

These are general examples of opening, reading, writing, and appending data files. The specific functions and their usage may vary depending on the programming language and file system being used.
Programming Paradigms: Procedural, Structured, and Object-Oriented
In computer programming, different paradigms represent different approaches to designing and structuring programs. Three commonly used programming paradigms are procedural, structured, and object-oriented programming (OOP). Let's explore each of these paradigms:
Procedural Programming:
In procedural programming, programs are organized around procedures or functions that contain a series of instructions to be executed in a specific order. The focus is on breaking down the program into smaller reusable functions, which are then called to perform specific tasks. Procedural programming emphasizes code reusability, modularity, and step-by-step execution of instructions.
The main characteristics of procedural programming include:
Structured Programming:
Structured programming builds upon procedural programming and introduces additional concepts to enhance code organization and maintainability. It emphasizes the use of control structures such as sequences, loops, and conditionals to improve program readability and avoid unstructured jumps or 'goto' statements.
The main characteristics of structured programming include:
Object-Oriented Programming (OOP):
Object-oriented programming (OOP) is a programming paradigm that focuses on modeling programs around objects, which are instances of classes. Objects encapsulate data and behavior, and interactions between objects occur through method calls and message passing. OOP promotes code reusability, encapsulation, and the concept of inheritance, allowing for the creation of complex and scalable software systems.
The main characteristics of object-oriented programming include:
Each programming paradigm has its own strengths and weaknesses, and the choice of paradigm depends on factors such as the nature of the problem, the development team's familiarity, and the requirements of the project.
Features of Object-Oriented Programming (OOP)
Object-oriented programming (OOP) is a programming paradigm that provides a set of features and principles for organizing and structuring software. These features enable developers to create modular, reusable, and maintainable code. Here are some key features of OOP:
These features of OOP collectively provide a powerful and flexible framework for software development. They promote code reusability, maintainability, and scalability, making it easier to manage and evolve complex software systems.
Advantages of Object-Oriented Programming (OOP)
Object-oriented programming (OOP) offers numerous advantages that contribute to the development of efficient, modular, and reusable software. Here are some key advantages of OOP:
These advantages make OOP a popular and widely adopted paradigm in software development. OOP helps in building robust, maintainable, and scalable applications by leveraging concepts such as modularity, code reusability, and encapsulation.
Applications of Object-Oriented Programming (OOP)
Object-oriented programming (OOP) is a versatile paradigm that finds applications in various domains of software development. Here are some common areas where OOP is extensively used:
These are just a few examples of the broad applications of OOP. OOP's versatility and scalability make it suitable for a wide range of software development scenarios, contributing to the development of robust and efficient solutions in various domains.
Software Project Concept
A software project concept refers to the high-level idea or vision behind a software development initiative. It involves identifying the problem or opportunity that the software aims to address, defining the objectives and scope of the project, and outlining the key features and functionalities of the desired software solution. The concept stage is crucial as it sets the foundation for the entire software development lifecycle. Here are some key aspects of a software project concept:
By defining a clear and well-thought-out project concept, stakeholders can align their expectations, make informed decisions, and provide a solid foundation for the subsequent stages of the software development process, such as requirements gathering, design, development, testing, and deployment.
Concept of Software Development Process
The software development process refers to a systematic approach or methodology followed to design, develop, test, and deploy software applications. It involves a series of steps and activities aimed at producing high-quality software solutions that meet the specified requirements and objectives. The software development process typically consists of the following key concepts:
It is important to note that different software development methodologies, such as Waterfall, Agile, or DevOps, may have variations in the order and emphasis placed on these concepts. The choice of methodology depends on factors such as project complexity, team size, customer requirements, and time constraints.
Following a well-defined software development process helps ensure the efficient and successful delivery of high-quality software solutions while managing risks, meeting timelines, and satisfying customer needs.
Concept of SDLC (Software Development Life Cycle)
The Software Development Life Cycle (SDLC) is a structured approach or framework that defines the stages and activities involved in the development of software applications. It provides a systematic and organized way to plan, design, build, test, and deploy software solutions. The SDLC consists of several distinct phases, each with its own objectives and deliverables. Here are the common phases of the SDLC:
The SDLC provides a structured approach to software development, ensuring that projects are well-planned, executed, and managed. It promotes collaboration, documentation, and quality assurance throughout the entire development process. By following the SDLC, organizations can deliver high-quality software solutions that meet user requirements, adhere to industry standards, and are delivered within budget and time constraints.
| System Analyst | Software Engineer |
|---|---|
| Focuses on analyzing and understanding the needs of users and organizations. | Focuses on designing, developing, and maintaining software applications. |
| Gathers requirements, conducts feasibility studies, and defines system specifications. | Translates requirements into software solutions, writes code, and implements software systems. |
| Identifies and analyzes business processes, user workflows, and system interactions. | Designs software architectures, data structures, algorithms, and user interfaces. |
| Collaborates with stakeholders to understand their needs and provide solutions. | Collaborates with cross-functional teams to develop software applications. |
| Performs system and data analysis to identify inefficiencies and recommend improvements. | Performs coding, debugging, and testing of software applications. |
| Creates system specifications, functional designs, and user documentation. | Writes code, creates technical documentation, and performs code reviews. |
| Ensures that the software solution aligns with business objectives and user requirements. | Ensures that the software solution is scalable, reliable, and meets technical standards. |
| May provide recommendations for system enhancements, upgrades, or replacements. | May provide recommendations for software architecture improvements or technology upgrades. |
Requirement Collection Methods
When gathering requirements for a software project, various methods can be used to collect information from stakeholders and users. The choice of requirement collection methods depends on factors such as project size, complexity, time constraints, and the nature of the project. Here are some common requirement collection methods:
It is common to use a combination of these requirement collection methods to ensure a comprehensive understanding of user needs and project requirements. The chosen methods should be tailored to the specific project and stakeholders involved, promoting effective communication, collaboration, and a clear vision of the desired software solution.
Concept of System Design
System design is a crucial phase in the software development life cycle (SDLC) where the overall architecture and detailed design of a software system are defined. It involves transforming the requirements gathered during the earlier stages into a concrete and well-structured design. The system design phase focuses on creating a blueprint for implementing the software solution effectively and efficiently. Here are the key aspects of system design:
The system design phase produces detailed technical specifications, architectural diagrams, design documents, and other artifacts that guide the implementation and development process. It serves as a reference for developers, ensuring that the software system is built according to the desired design principles and requirements. A well-executed system design lays the foundation for a robust, scalable, and maintainable software system.
Software and Quality
Quality is a critical aspect of software development as it determines the reliability, performance, and user satisfaction of the software product. Software quality encompasses various dimensions, including functionality, reliability, usability, efficiency, maintainability, and security. Here are some key considerations related to software quality:
To achieve high-quality software, various practices and techniques are employed throughout the software development life cycle. These include requirements gathering and validation, thorough testing and quality assurance, code reviews and inspections, adherence to coding standards and best practices, and continuous monitoring and improvement.
Investing in software quality not only enhances the user experience but also reduces risks, improves reliability, and increases customer satisfaction. High-quality software leads to better performance, increased productivity, and long-term cost savings by reducing the need for rework, bug fixes, and maintenance.
Software Development Models: Waterfall, Prototype, Agile
Software development models are systematic approaches used to guide the development process and manage the lifecycle of a software project. Here are three commonly used software development models: Waterfall, Prototype, and Agile.
| Model | Description | Advantages | Disadvantages |
|---|---|---|---|
| Waterfall Model | The Waterfall model follows a linear and sequential approach to software development. It consists of distinct phases such as requirements gathering, design, implementation, testing, and maintenance. Each phase is completed before moving on to the next. |
|
|
| Prototype Model | The Prototype model focuses on developing an initial working version of the software quickly to gather feedback and refine requirements. It involves iterative cycles of prototyping, feedback collection, and refinement. |
|
|
| Agile Model | The Agile model emphasizes flexibility, collaboration, and iterative development. It promotes adaptive planning, continuous improvement, and delivering working software in short development cycles called sprints. Agile frameworks such as Scrum and Kanban are commonly used. |
|
|
Each software development model has its own strengths and weaknesses, and the choice of model depends on project characteristics, team dynamics, customer involvement, and other factors. It is important to select the most suitable model and adapt it as necessary to ensure successful software development and delivery.
Concept of AI and Robotics
Artificial Intelligence (AI) and Robotics are two closely related fields that deal with the development and utilization of intelligent machines. Here's an overview of these concepts:
Artificial Intelligence (AI):
AI refers to the development of computer systems that can perform tasks that typically require human intelligence. It involves the creation of algorithms, models, and systems that can perceive, reason, learn, and make decisions. AI techniques include machine learning, natural language processing, computer vision, expert systems, and more. AI has applications in various domains, including healthcare, finance, autonomous vehicles, gaming, and virtual assistants.
AI systems can analyze vast amounts of data, recognize patterns, and make predictions or recommendations. They can understand and generate human-like speech, interpret images and videos, and even exhibit advanced cognitive capabilities. AI has the potential to revolutionize industries, improve efficiency, enhance decision-making processes, and unlock new possibilities for innovation.
Robotics:
Robotics focuses on the design, development, and application of physical robots or machines that can interact with the physical world. Robots are typically equipped with sensors, actuators, and a control system to perceive their environment, make decisions, and perform tasks autonomously or under human guidance. Robotics combines elements from various fields such as mechanical engineering, electronics, computer science, and AI.
Robots can be found in various industries and settings, ranging from industrial manufacturing and logistics to healthcare and domestic environments. They can perform repetitive or dangerous tasks with precision, work in environments unsuitable for humans, assist in surgeries, explore hazardous locations, and provide assistance to individuals with disabilities. Advanced robots incorporate AI capabilities, allowing them to adapt, learn, and interact intelligently with humans and their surroundings.
AI and Robotics often intersect, with AI playing a crucial role in enhancing the intelligence and autonomy of robots. By integrating AI techniques, robots can acquire new skills, learn from experience, recognize objects and gestures, and collaborate with humans more effectively.
Together, AI and Robotics have the potential to revolutionize industries, transform our daily lives, and address complex challenges by creating intelligent machines capable of performing tasks that were once exclusively in the realm of human capabilities.
Concept of Cloud Computing
Cloud computing is a model for delivering computing resources and services over the internet on-demand. It enables users to access and utilize a shared pool of computing resources, including networks, servers, storage, applications, and services, without the need for direct ownership or management of the underlying infrastructure. Here's an overview of the concept of cloud computing:
Key Characteristics of Cloud Computing:
Deployment Models:
Cloud computing offers different deployment models to suit various needs and requirements:
Benefits of Cloud Computing:
Cloud computing has transformed the IT landscape, providing organizations with flexible and cost-effective solutions for storage, processing, and accessing computing resources. It has enabled innovation, agility, and scalability while reducing the burden of infrastructure management and maintenance.
Concept of Big Data
Big Data refers to large and complex datasets that are difficult to process and analyze using traditional data processing techniques. The concept of Big Data is characterized by the three V's: Volume, Velocity, and Variety. Here's an overview of the concept of Big Data:
Volume:
Volume refers to the vast amount of data generated from various sources such as social media, sensors, devices, transactions, and more. Big Data encompasses datasets that are too large to be stored, processed, or analyzed using traditional database management systems and tools. The volume of data continues to grow exponentially, posing challenges in terms of storage, processing power, and scalability.
Velocity:
Velocity refers to the speed at which data is generated, collected, and processed. With the increasing number of connected devices and real-time data sources, data is being generated at a tremendous speed. Big Data systems need to be capable of capturing, processing, and analyzing data in near real-time to extract valuable insights and enable timely decision-making.
Variety:
Variety refers to the diverse types and formats of data that exist within Big Data. Data can come in structured, semi-structured, and unstructured formats. Structured data is organized and follows a predefined schema, such as data stored in relational databases. Semi-structured data has some organization but does not conform to a rigid schema, such as JSON or XML files. Unstructured data, on the other hand, has no predefined structure and includes text documents, images, videos, social media posts, sensor data, and more. Big Data systems need to handle and process this variety of data formats to extract meaningful insights.
Challenges and Opportunities:
The concept of Big Data presents both challenges and opportunities for organizations:
Big Data has significant implications across various industries, including finance, healthcare, marketing, transportation, and more. By harnessing the power of Big Data, organizations can gain deeper insights, improve operational efficiency, enhance customer experiences, and drive innovation.
Concept of Virtual Reality
Virtual Reality (VR) refers to an immersive computer-generated environment that simulates a realistic experience, often involving the use of headsets or other devices. It aims to create a sense of presence and interaction in a virtual world that can be similar to or completely different from the real world. Here's an overview of the concept of Virtual Reality:
Key Components of Virtual Reality:
Applications of Virtual Reality:
Virtual Reality has found applications in various fields, including:
Advantages of Virtual Reality:
Virtual Reality continues to evolve and advance, offering exciting possibilities for various industries and transforming the way we experience and interact with digital content.
Concept of E-commerce
E-commerce, short for electronic commerce, refers to the buying and selling of goods and services over the internet. It involves online transactions between businesses, consumers, or a combination of both. Here's an overview of the concept of e-commerce:
Key Components of E-commerce:
Types of E-commerce:
Advantages of E-commerce:
E-commerce has revolutionized the way businesses operate and consumers shop. It has transformed the retail industry and continues to evolve with technological advancements and changing consumer expectations.
Concept of E-medicine
E-medicine, also known as telemedicine or telehealth, refers to the delivery of healthcare services, medical consultations, and information through electronic communication channels. It utilizes technology to overcome geographical barriers and provide remote healthcare solutions. Here's an overview of the concept of e-medicine:
Key Components of E-medicine:
Applications of E-medicine:
Advantages of E-medicine:
E-medicine is revolutionizing the healthcare industry, improving access to care, and transforming the way healthcare services are delivered. It offers opportunities for remote healthcare delivery, patient empowerment, and the optimization of healthcare resources.
Concept of Mobile Computing
Mobile computing refers to the use of portable computing devices, such as smartphones, tablets, and wearable devices, to access and perform computing tasks while on the move. It involves the mobility of both the hardware devices and the users themselves. Here's an overview of the concept of mobile computing:
Key Components of Mobile Computing:
Applications of Mobile Computing:
Advantages of Mobile Computing:
Mobile computing has revolutionized the way we communicate, access information, and perform various tasks in our daily lives. It has opened up new possibilities for convenience, connectivity, and productivity, making it an integral part of the modern digital world.
Concept of Internet of Things (IoT)
The Internet of Things (IoT) refers to the network of interconnected physical devices, objects, and sensors that are embedded with sensors, software, and connectivity capabilities to collect and exchange data over the internet. These devices can communicate and interact with each other, enabling them to gather and share information for various applications. Here's an overview of the concept of IoT:
Key Components of IoT:
Applications of IoT:
Advantages of IoT:
The Internet of Things has the potential to transform industries, improve everyday life, and create new opportunities for innovation and connectivity. It continues to evolve, with advancements in connectivity, data analytics, and artificial intelligence, driving its adoption and impact on various sectors.

